This week, we had a case at my library where we wanted to extract the full-text field for a few of our digital collections and save it as a separate text file for each image. Normally, we create text files for images by running OCR on them outside of CONTENTdm. But for a few collections, transcriptions were manually created and entered into the Full Text field directly in CONTENTdm. We wanted to transfer those transcriptions from the CONTENTdm metadata to plain text files that we can preserve separately, both as a backup and in preparation for a future migration.
I thought that other people might have a similar use case for this workflow, and wanted to make sure and save it for myself, so I decided to write up some quick documentation here. I’m fairly confident that there are other, possibly much simpler, ways to do this, but this was a method that I could do using tools that I already (mostly) was familiar with.
First, export the metadata for the collection from CONTENTdm, and open it in Excel. Then copy two columns into a new spreadsheet:
- Column A should contain containing the identifiers, which will become the filenames for the text files (for us, these are our “Digital IDs”, which match the filenames of the corresponding TIFFs)
- Column B should be the full text transcription (for us, this is simply called “Full Text”
Delete any rows without text in the Full Text column, using “Go To Special”

To save each row as its own text file, I used a quick macro that I adapted from responses to a Stack Overflow question. The macro saves each cell in Column B as a txt file, with the value of Column A as the filename:
Sub savemyrowsastext()
Dim saveText As String
For Each cell In Sheet1.Range(“A1:A” & Sheet1.UsedRange.Rows.Count)
saveText = cell.Text
Open “C:\Users\ewilliams\Desktop\” & saveText & “.txt” For Output As #1
Print #1, cell.Offset(0, 1).Text
Close #1
Next cellMsgBox (“Done”)
End Sub
Ta-dah! Now you have text files for each page/image in CONTENTdm!
In looking through the text files, though, I realized that the line breaks in the transcriptions got lost in the process. (I suspect CONTENTdm doesn’t output the line breaks in the metadata at all, which makes sense.) I wanted those line breaks, though, since they were present in the transcriptions in CONTENTdm, and help make the transcriptions more user-friendly.
Looking at the files, I discovered that in the exported metadata, what showed up in the CONTENTdm front-end as two line breaks was turned into four blank spaces. I can’t guarantee that is how CONTENTdm will always export that, but it was in my case.
Well, that should be easy enough to fix en masse using the command line. After googling around and testing various ways of manipulating text files on the command line, I settled on using the sed command. (Various attempts to use the tr command or perl didn’t work, for reasons I wasn’t willing to put the time into figuring out.) I did a little more research/refreshing on how to encode newline characters, and ended up with this:
sed –i ‘s/ /\r\n\r\n/g’ *.txt
It’s worth noting that sed only works on a bash shell (I use Git Bash). It’s also a good idea to make backups of the text files before running this, just in case something goes wrong (although you could always just re-export them from the Excel file).
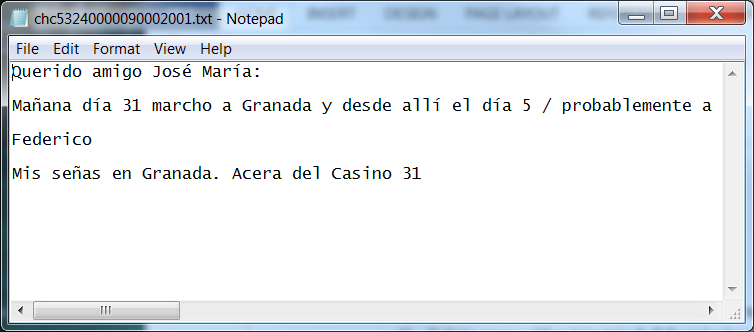
So that’s it. Relatively straight-forward, although as I mentioned, I’m sure there are quicker/cleaner ways to do it. I’d love to hear any feedback or suggestions for how to improve this process!
Thanks so much for this Elliot! This exact use case just came up for me.
Awesome! I’m so glad it was helpful for you, Anna! 🙂